Der logische Datenbankentwurf mit dem Relationenmodell
https://bildung.social/deck/@oerinformatik/114409653813500714
https://oer-informatik.de/relationenmodell
tl/dr; (ca. 8 min Lesezeit): Im logischen Modell legen wir uns fest, wie die logische Verknüpfung der Daten untereinander umgesetzt werden soll. Im Relationenmodell erfolgt dies über Schlüsselattribute. Dieser Artikel erklärt die unterschiedlichen Wege, Schlüsselattribute zu bestimmen, die Transformationsregeln, um die Beziehungstypen des Entity-Relationship-Modells in Schlüsselbeziehungen umzusetzen und führt Constraints ein, die Attributen im logischen Modell zugeordnet werden. (Zuletzt geändert am 29.04.2025)
Schon fit in diesem Thema? Nutze die Kann-Liste und die Leitfragen unter dem Artikel als Checkliste, ob Du die relevanten Kompetenzen bereits hast.
Als Modellierungs-Grundlagen kann ich nach Durchlesen des Artikels…
… die Aufgabe der logischen Datenbankmodellierungsphase erklären.
… unterschiedliche logische Datenmodelle nennen.
… erklären, welche Eigenschaften Primärschlüsselkandidaten haben müssen.
… mich kriteriengestützt entscheiden, ob im Modell natürliche und künstliche Primärschlüssel genutzt werden sollen.
… unterschiedliche Arten künstlicher Primärschlüssel und deren Vor- und Nachteile nennen.
… erklären, was zusammengesetzte Primärschlüssel, Teilschlüssel und Indizes sind.
… erklären, was ein Fremdschlüssel ist.
… Relationenmodelle tabellarisch oder textuell unter Nennung von Schlüsseln und Constraints darstellen.
… ein Entity-Relationship-Modell in ein Relationenmodell überführen, in dem ich…
… Entitätstypen in Relationenschema überführe.
… Primärschlüsselkandidaten identifiziere und daraus Primärschlüssel bestimme.
… die Schritte zur Transformation für 1:n Beziehungen nenne und diese durchführe.
… die Schritte zur Transformation für m:n Beziehungen nenne und diese durchführe.
… Kriterien nenne, die für die Auswahl des Transformationswegs einer 1:1-Beziehung relevant sind, einen geeigneten Weg auswähle, die Schritte zur Transformation nenne und diese abschließend durchführe.
… alle genannten Transformationen um Optionalität ergänze, wenn nötig.
Darüber hinaus kann ich als Modellierungs-Expertenwissen…
… erklären, was ein Surrogatschlüssel ist.
… die Vorteile von Schlüsseln über UUIDs nennen.
… bestehende Constraints (Optionalität, abgeleitete Attribute, schwache Schlüssel) in ein Relationenmodell überführen.
… notwendige neue Constraints (unikal, eingabepflichtig) in ein Relationenmodell ergänzen.
Vom konzeptuellen ins logische Modell
Im konzeptuellen Modell (dem Entity Relationship Model) wurden die abzubildenden Daten aus der realen Welt in Form von Entitätstypen und Attributen abstrahiert und strukturiert. Dabei erfolgte noch keine Festlegung in welcher Art Datenbank die Daten gespeichert werden sollen: ob beispielsweise als XML-Datei, in einer hierarchischen Datenbank oder eben einer relationalen Datenbank. Diese Festlegung auf ein logisches Datenbankmodell erfolgt zu Beginn des nächsten Entwurfsschritts: im logischen Datenmodell.

Es gibt eine Vielzahl unterschiedlicher Datenmodelle mit einer noch größeren Vielzahl konkreter Programme (Implementierungen). Die bekanntesten Vertreter sind:
Hierarchisches Modell (z.B. Dateisystem – jeder Datensatz hat genau einen Vorgänger)
Netzwerkmodell (mehrere Vorgängerdaten, Struktur bei Datenabfrage festgelegt)
Relationales Modell (in Beziehung stehende Tabellen)
Objektorientiertes Modell (Objekte aus OOP können in DB gespeichert werden)
Objekt-relationales Modell (relationales Modell, das Vererbung zulässt)
Semistrukturiertes Modell / schemafreie DB (Struktur der Datenelemente ist nicht festgelegt (z.B. schemafreies XML, JSON)
Transformation des konzeptuellen Modells in ein relationales logisches Modell: das Relationenmodell
Informationen aus dem ER-Modell
Welche Eigenschaften werden im Entity-Relationship-Modell beschrieben, die übertragen werden müssen?
Entitätstypen
Attribute
Beziehungen (1:1, 1:N, M:N)
Optionalitäten der Beziehungen (1:C, 1:NC, M:NC)
Mehrwertigkeit von Attributen
Schwache Entitätstypen und identifizierende Relationen
Schwache Schlüsselattribute
abgeleitete Attribute
Transformationsschritte
Primärschlüssel wählen
Für jeden Entitätstyp muss ein Primärschlüssel (primary key) gefunden werden, der jede Entität eindeutig identifiziert.
Primärschlüssel können sich aus einem oder einer Kombination mehrerer Attribute ergeben. Primärschlüsselkandidat sind alle Attribut(-kombinationen), die für jede einzelne Entität einzigartig (unique) ist. Geeignete zusammengesetzte Primärschlüsselkandidaten enthalten nur so viele Attribute, wie zur Identifizierung einer Entität erforderlich. Neben den natürlichen Schlüsseln, die sich aus vorhandenen Attributen ergeben, besteht auch noch die Möglichkeit, künstliche Primärschlüssel zu vergeben. Diese sogenannten Surrogatschlüssel können beispielsweise fortlaufende Nummern oder anderweitig erzeugte (Hash-)werte sein.
Aus den so gebildeten Schlüsselkandidaten kann ein Primärschlüssel ausgewählt werden.
Kardinalitäten in Fremdschlüsselbeziehungen transformieren
Die Beziehungen zwischen Entitätstypen werden im ER-Modell als Assoziation mit Kardinalitäten modelliert.
Im Relationenmodell werden sie in Fremdschlüsselbeziehungen transformiert: die Primärschlüssel einer Relation werden in einer zweiten Relation als Attribut gelistet - dort erhalten sie die Bezeichnung “Fremdschlüssel” (foreign key).
Die ersten Transformationsschritte sind für alle Arten von Entitätstypen identisch:
Aus allen Entitätstypen werden Relationen. Oft werden diese ale einfacher Text erfasst, klein geschrieben und mit dem Plural bezeichnet:
schülerInnen()Alle zugehörigen Attribute der Entitätstypen werden hinter dem Relationennamen in Klammern kommagetrennt gelistet:
schülerInnen(SchülerInID, Vorname, Nachname)Die Primärschlüsselattribute werden unterstrichen oder mit PK (für primary key) annotiert:
schuelerInnen(SchülerInID (PK), Vorname, Nachname)
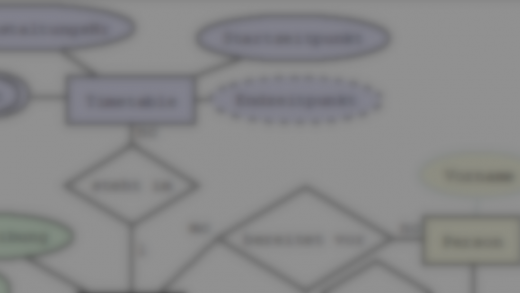
Transformation einer Assoziation mit 1:N - Kardinalität
Als Beispiel dient die Assoziation zwischen den Entitätstypen Schüler*in und Klasse:

Zunächst werden beide Entitätstypen wie oben unter 1.-3. beschreiben in Relationen umgewandelt, dann folgt die Umwandlung der Assoziation und Kardinalität:
- Bei
1:N-Beziehungen wird der Primärschlüssel der Relation, bei der die Kardinalität “1” steht als Fremdschlüsselattribut in die Relation, bei der das “N” steht aufgenommen. Fremdschlüsselattribute werden mit Pfeil nach oben gekennzeichnet oder mit FK (foreign key) annotiert:
Relationenschema für 1:N-Beziehungen
schülerInnen (SchülerInID, Vorname, Nachname ↑Klassenbezeichnung↑)
klassen (Klassenbezeichnung, KlassenlehrerIn)
oder in Textform ohne Formatierungen und Sonderzeichen:
schülerInnen (SchülerInID (PK), Vorname, Nachname, Klassenbezeichnung (FK))
klassen (Klassenbezeichnung (PK), KlassenlehrerIn)Transformation einer Assoziation mit M:N - Kardinalität
Eine Assoziation mit einer Vielfachheit zu beiden Seiten (M:N) wird am Beispiel der Entitätstypen Lehrer*in und Klasse dargestellt:

Auch hier werden zunächst beide Entitätstypen wie oben unter 1.-3. beschreiben in Relationen umgewandelt, danach folgt die Umwandlung der Assoziation und Kardinalität:
- Im Fall einer
M:N-Beziehung wird eine neue Relation gebildet. Diese zusätzliche Relation erhält die Primärschlüssel beider verknüpfter Relationen als zusammengesetzten Primärschlüssel. Diese beiden Attribute sind zugleich Fremdschlüssel.
Relationenschema für M:N-Beziehungen
lehrerInnen (LehrerInID, Vorname, Nachname)
klassen (Klassenbezeichnung, Jahrgangsstufe)
unterrichte (↑LehrerInID↑, ↑Klassenbezeichnung↑)
bzw. in Reintextform:
lehrerInnen (LehrerInID (PK), Vorname, Nachname)
klassen (Klassenbezeichnung (PK), Jahrgangsstufe)
unterrichte (LehrerInID(PK, FK), Klassenbezeichnung(PK, FK))Transformation einer Assoziation mit 1:1 - Kardinalität
Relativ selten kommt es in der Praxis vor, dass zwei Entitätstypen in einer 1:1-Beziehung zueinander stehen. Bei der Umwandlung in das Relationenmodell ergeben sich hier eine Reihe von Möglichkeiten, die anhand des Beispiels Einwohner und Personalausweis dargestellt werden:

Möglichkeit 1: Zusammenfassung in einer Relation
In der Regel ist es am einfachsten, die beiden Entitätstypen in einer gemeinsamen Relation zusammenzufassen, wobei nur einer der beiden Primärschlüssel in der neuen Relation diese Funktion übernimmt (der zweite bleibt als unikales - also einzigartiges - Attribut vorhanden).
- einwohner (SozialversicherungsNr, Vorname, Nachname, PersoNr (unikal), Ausstellungsdatum, Gültigkeit)
Möglichkeit 2: zwei Relationen mit gemeinsamem Primärschlüssel
Denkbar ist auch, dass zwei Relationen gebildet werden, die beide den gleichen Primärschlüssel verwenden. Diese Variante wäre zu bevorzugen, wenn einer der beiden Entitätstypen sehr selten zugeordnet würde und dieser vergleichsweise teuer ist (also Daten-/Ressourcen-aufwändig). Würde also beispielsweise ein hoch aufgelöstes Passbild gespeichert bei den wenigen Einträgen der Personalausweise, wobei sehr viele Einwohner ohne Personalausweis existieren, dann wäre dies der Weg der Wahl.
einwohner (↑SozialversicherungsNr↑, Vorname, Nachname)
personalausweise (↑SozialversicherungsNr↑, PersoNr (unikal), Ausstellungsdatum, Gültigkeit)
Möglichkeit 3: Primärschlüssel als Fremdschlüssel, dieser muss unikal sein
Eine dritte, aber Fehler anfälligere Variante geht von zwei Relationen mit unterschiedlichen Primärschlüsseln aus, die über einen Fremdschlüssel verknüpft sind. Damit auf diesem Weg keine 1:N-Beziehung modelliert wird und die Datenbank inkonsistent wird muss dieser Fremdschlüssel jedoch unikal, also in der Eingabe einzigartig, sein. Diesen Weg sollte man nur wählen, wenn man weiß, was man tut.
einwohner (↑SozialversicherungsNr↑, Vorname, Nachname)
personalausweise (PersoNr, ↑SozialversicherungsNr↑ (unikal), Ausstellungsdatum, Gültigkeit)
Möglichkeit 4: Verknüpfungstabelle mit zusammengesetztem Primärschlüssel, in dem beide Teilschlüssel unikal sein müssen
Eine vierte Variante ist sachgerecht, wenn beide Entitätstypen optional sind, es also im Beispiel sowohl Einwohner ohne Personalausweis als auch Personalausweise ohne Einwohner gibt. Hierbei wird analog zur M:N-Beziehung eine Zwischenrelation erstellt, bei der beide Primärschlüssel der Einzelrelationen als Fremdschlüssel übernommen werden und gemeinsam den zusammengesetzten Primärschlüssel der neuen Relation ergeben. Um Mehrfachzuordnungen auszuschließen ist auch hier wichtig, dass die beiden Teilschlüssel in der Zwischentabelle unikal sind.
einwohner (SozialversicherungsNr, Vorname, Nachname)
personalausweise (PersoNr, Ausstellungsdatum, Gültigkeit)
einwohner2personalausweise (↑PersoNr↑ (unikal), ↑SozialversicherungsNr↑ (unikal))
Die hier in allen Beispielen genannte Einzigartigkeit (unikal / unique) muss im Relationenmodell explizit genannt werden!
Transformation von schwachen Entitätstypen mit identifizierender Assoziation

Sofern zur Identifizierung einer Entität neben einem Attribut des Entitätstyps eine Beziehung zu einem anderen Entitätstyp nötig ist, spricht man von einem schwachen Entitätstypen. Die Rechnungsposition “1” existiert auf mehreren Rechnungen, daher ist zur genauen Identifizierung die Kenntnis wichtig, um welche Rechnung es sich handelt. Rechnungsposition ist in diesem Fall ein schwacher Schlüssel, Rechnungsposten ein schwacher Entitätstyp und enthält ist eine identifiziernde Beziehung.
Der schwache Entitätstyp wird in diesem Fall als Relation mit zusammengesetztem Primärschlüssel modelliert, wobei der eine Teilschlüssel dem Fremdschlüssel aus der identifizierenden Beziehung entspricht und der zweite Teilschlüssel der schwache Schlüssel des Ausgangs-Entitätstyps ist.
Relationenschema für schwache Relationen in 1:N-Beziehungen:
rechnungen(Rechnungsnummer, Rechnungsanschrift, Datum)
rechnunsposten (Rechnungsposition, ↑Rechnungsnummer↑, Preis, Anzahl, Artikel)
Optionalitäten transformieren
Bei Kardinalitäten, die mit Optionalität formuliert sind (1:C, 1:NC, N:MC) wird die Optionalität in der Regel über die nicht verpflichtende Eingabe eines Fremdschlüssels modelliert. Primärschlüsselattribute gelten immer als eingabepflichtig, alle anderen Attribute (inkl. Fremdschlüssel) gelten als nicht eingabepflichtig.
Sofern für Nichtschlüsselattribute eine Eingabepflicht festgelegt werden soll kann dies durch explizite Angabe von NOT NULL dokumentiert werden, einige CASE-Tools notieren eingabepflichtige Attribute fett, Attribute ohne Eingabepflicht in normaler Schreibweise.
Alternative Schreibweisen
Da sowohl die Pfeile für Fremdschlüssel als auch die Unterstreichungen für Primärschlüssel nicht in jedem System darstellen lassen, gibt es eine Reihe abweichender Notationsformen für Relationenmodelle.
Am häufigsten anzutreffen ist die Notation als Tabelle mit Kennzeichnung der Schlüssel über Schlüsselsymbole oder “FK” und “PK”. Einzigartigkeit wird dann häufig mit uniq, Eingabepflicht mit NOT NULL oder Sternchen * angegeben. Viele CASE-Tools zum Datenbankentwurf setzen dies so um, auch in den IHK Abschlussprüfungen für Fachinformatiker*innen ist dies häufig so anzutreffen:

Häufig wird zur Verdeutlichung der Fremdschlüsselbeziehungen noch eine Verbindungslinie mit Martin-notierten Kardinalitäten (“Krähenfuß”) ergänzt. Diese Information ist aber redundant, da die Fremdschlüssel bereits die Beziehungen wiedergeben.
PlantUML für Relationenschema verwenden:
Mit dem UML-Werkzeug plantUML lassen sich auch Relationenschema mit Schlüsselbeziehungen abbilden. Bei einigen Symbolen muss auf die HTML-notierten Unicode-Zeichen zurückgegriffen werden. In folgendem Beispiel wurden bewusst mehrere redundante Wege der Kennzeichnung aufgezeigt - natürlich genügt zu Dokumentationszwecken eine der genannten Hervorhebungen:

Erstellt werden können die plantUML-Diagramme beispielsweise über den Webdienst planttext (wie z.B. die obige Grafik über diesen Link) IDE-Plugins oder git*-Dienste wie bitbucket, gitlab oder github.
Der Quelltext zur Erstellung des obigen Relationenschemas wäre etwa:
@startuml
hide circle
skinparam classAttributeIconSize 0
entity "entity" {
⚷ PrimaryKey attribute <<PK>>
↑ ForeignKey attribute <<FK>>
* <b>mandatory attribute</b> <<NOT NULL>>
optional attribute
① unique attribute <<UNIQ>>
}
@endumlWeitere Tools zur Erstellung eines Relationenschemas
- dbdiagram.io ist ein weiteres Onlinetool, um relationale Datenmodelle darzustellen
Leitfragen
Welche Transformationsregeln gelten für den Übergang vom ER- zum Relationenmodell jeweils für Assozitationen der Kardinalität 1:1, 1:n und n:m?
Warum wird in den Notationen nach Chen und Krähenfuß die Kardinalität nur allgemein angegeben (z.B. Auto zu Räder 1:n statt 1..4 wie im UML-Klassendiagramm)?
Was versteht man unter einem Primär- und Fremdschlüssel und wie werden diese im Relationenschema dargestellt?
Was versteht man unter natürlichen Schlüsseln, Teilschlüsseln, zusammengesetzten Schlüsseln und Schlüsselkandidaten?
Links und weitere Informationen
- eine detaillierte Liste aller Transformationsregeln - vor allem inkl. der Sonderfälle für rekursive und optionale Beziehungen findet sich u.a. im “Grundkurs Datenbankentwurf” von Helmut Jarosch, 4. Auflage 2016
Hinweis zur Nachnutzung als Open Educational Resource (OER)
Dieser Artikel und seine Texte, Bilder, Grafiken, Code und sonstiger Inhalt sind - sofern nicht anders angegeben - lizenziert unter CC BY 4.0. Nennung gemäß TULLU-Regel bitte wie folgt: “Der logische Datenbankentwurf mit dem Relationenmodell” von , Lizenz: CC BY 4.0. Der Artikel wurde unter https://oer-informatik.de/relationenmodell veröffentlicht, die Quelltexte sind in weiterverarbeitbarer Form verfügbar im Repository unter https://gitlab.com/oer-informatik/db-design/relationenmodell. Stand: 29.04.2025.
[Kommentare zum Artikel lesen, schreiben] / [Artikel teilen] / [gitlab-Issue zum Artikel schreiben]