Persistenzschicht und Modell
https://bildung.social/@oerinformatik/
https://oer-informatik.de/sbb03_addressmodel
tl/dr; _(ca. 6 min Lesezeit): Es werden die Abhängigkeiten für ein Model angefügt, eine Modelklasse erstellt und annotiert. Die OOP-Hintergründe für Repositories werden kurz an UML-Klassendiagrammen erläutert. Dieser Artikel ist ein Teil der Artikelserie zu einem Adressbuch-SpringBoot-Projekt. Weiter geht es dann mit dem Test des Modells über das Repository: Testen des Repositories.
Konfiguration und Abhängigkeiten
Der Ablauf beim Einfügen einer neuen Komponente ist bei Spring(Boot) weitgehend identisch:
Abhängigkeiten in der
pom.xml(Maven) bzw.build.gradle(Gradle) eintragenneue Klasse erzeugen, die mit einer
@Component-Annotation annotiert wirdKonfigurationen anpassen - z.B. über
application.propertiesim Ordnersrc/main/ressources
Um ein Model mit zugehörigem Datenspeicher (Persistenzschicht) zu erstellen müssen zwei Abhängigkeiten ergänzt werden:
Spring Data JPA
Eine Persistence Unit - hier der Einfachheit halber zunächst die in-memory-Datenbank H2
Folgende Abschnitte müssen in der pom.xml vorhanden sein:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>(NB: händisch reinkopieren, IJ: kopieren oder über Code/Generate => Dependency nach “spring-boot-starter-data-jpa” und “com.h2database” suchen)
Gliederung des Projekts in Packages
Es bestehen für ein Projekt zwei grundsätzliche Ansätze, wie die einzelnen Klassen in Packages strukturiert werden:
Gliederung nach Begriffen der Problem- oder Fachdomäne: alle Klassen, die zu einem bestimmten Teil der Fachdomäne gehören werden in einem Package zusammengefügt. Also etwa alle Dateien, die eine Adresse verarbeiten.
Gliederung nach Komponenteneingenschaften: Klassen, die einen gemeinsamen Concern behandeln werden in Packages zusammengefasst: also etwa alle Controller, alle Models und alle Views.
Für beide Varianten gibt es Vor- und Nachteile. Wir erstellen hier eine Struktur basierend auf der Fachdomäne: alle Adress-Klassen werden in einem Package zusammengefasst.
Hierzu muss zunächst ein neues Package erstellt werden, also zunächst ein neuer Ordner unterhalb von addressbook (Rechtsklick) mit Namen address:


Die Modell-Klasse
Die neu angelegte Klasse hat bereits einen Rumpf:
Dieses Modell wird als POJO umgesetzt, das zusätzlich mit Annotationen versehen wird. Als POJO (Plain Old Java Object) im engeren Sinne werden einfache Java-Klassen verstanden, die nur von Object erben, keine Interfaces implementieren und nicht annotiert sind. Häufig verfügen POJOs nur über Attribute, Getter und Setter.
Ein Model wird mit der Annotation @Entity versehen - und damit hat JPA im Prinzip schon alle Information, die es benötigt.
Damit die Annotation @Entity bekannt ist muss nur noch die Persistenzumgebung importiert werden. Schließlich liegt die Annotation im Paket javax.persistence:
Trägt die Tabelle in der Datenbank einen anderen Namen als die Klasse (z.B. das deutsche Adressen statt englisch address), so kann dieser mit der Annotation @Table(name = "Adressen") festgelegt werden.
Es folgt die Deklaration der Attribute:
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String firstName;
private String lastName;
private String street;
private String streetAdditional;
private String postalCode;
private String city;
private String country;Auch die Felder können annotiert werden, i.d.R. ist dies aber nur beim Primärschlüssel (id) erforderlich. Die Annotation @Column bietet einige Parameter, die interessant sein könnten:
String name: Der Name des Attributs in der Tabelle (Spaltenname) weicht vom Klassenattributnamen abboolean unique: beiunique=truemuss der Wert einzigartig seinboolean nullable: beinullable=falsedarf der Attributwert nichtNULLseinboolean updatable / insertable: Attribut wird in UPDATE / INSERT-Befehlen ignoriert, wenn diese flag expizit auffalsegestellt wird (updatable=false)String table: Wenn dieses Attribut in einer anderen Tabelle als die Primäre Tabelle gespeichert wird, kann der Name hier angegeben werden.int length: Wenn die Zeichenlänge eines Strings von max. 255 abweicht, dann dies hiermit angegeben werden.int precision / scale: Gibt die Anzahl der Nachkommastellen an, falls der DatentypDecimalgenutzt wird (muss analog zur Angabe per DDL gesetzt werden)
Eine sinnvolle Annotation eines Attributs könnte also sein:
Darüber hinaus müssen Konstruktoren eingefügt werden: ein Default-Konstruktor (weil die JPA es verlangt, dieser wird jedoch nicht genutzt) und ein Konstruktor, der alle Attribute setzt, die nicht mit @GeneratedValue annotiert sind:
VSCode bietet uns im Kontextmenü (rechte Maustaste im Editorfenster beim Klick auf einen Attributnamen) unten den Punkt “Quellaktion” an, der einiges vereinfachen wird:

Damit lassen sich zunächst alle Getter und Setter, später auch der Konstruktor setzen.

Im Fall des Konstruktors sollten alle Attribute bis auf id ausgewählt werden.
Den Default-Konstruktor ohne Parameter müssen wir manuell eingeben. Die beiden Konstruktoren wären also etwa:
public Address(){
}
public Address(String firstName, String lastName, String street, String streetAdditional,
String postalCode, String city, String country) {
this.firstName = firstName;
this.lastName = lastName;
this.street = street;
this.streetAdditional = streetAdditional;
this.postalCode = postalCode;
this.city = city;
this.country = country;
}Wir ergänzen noch einen abgekürzten Konstruktor, damit wir auch Objekte nur mit Vorname und Nachname bilden können:
public Address(String firstName, String lastName){
this(firstName, lastName, "Musterstraße", "123",
"10435", "Berlin", "Deutschland");
}Es gehört zum guten Stil, dass man die toString()-Methode ebenso überschreibt und alle relevanten Attribute ausgibt (Auch hier hilft die Codegenerierung von oben):
@Override
public String toString() {
return "Address [city=" + city + ", country=" + country + ", firstName=" + firstName + ", id=" + id
+ ", lastName=" + lastName + ", postalCode=" + postalCode + ", street=" + street + ", streetAdditional="
+ streetAdditional + "]";
}Erstellen eines neuen Repositories
Eigentlich weiß Springboot jetzt alles, was es wissen muss, um Instanzen von Address zu erzeugen und deren Attribute in einer Datenbank zu speichern. Es fehlen nur noch Methoden, die die Create, Read, Update und Delete- Aktionen (CRUD) für die Datenbank implementieren. Eine Klasse, die genau das tut, nennt sich ein Repository.
Repositories sind Komponenten, die bestimmte fachliche Klassen verwalten. Um die Implementierung müssen wir uns aber nicht mehr kümmern, das übernimmt das Framework. Wir legen lediglich ein Interface an, SpringBoot implementiert die fehlenden Methoden an Hand des übergebenen Models zur Laufzeit automatisch.
Im address-Ordner legen wir eine neue Datei AddressRepository.java an. In der Datei definieren wir ein Interface, legen fest, dass es vom CrudRepoistory erbt (eine Vorlage von Spring), sowie, dass die generische Typparameter das Address und der id-Typen Long sind:
package de.csbme.ifaxx.addressbook.address;
import org.springframework.data.repository.CrudRepository;
public interface AddressRepository extends CrudRepository<Address, Long> {}Der Rest passiert per Zauberhand: Das Spring-Framework implementiert (vereinfacht gesagt) zur Laufzeit eine konkrete Klasse, die unsere Address-Klasse nutzt:
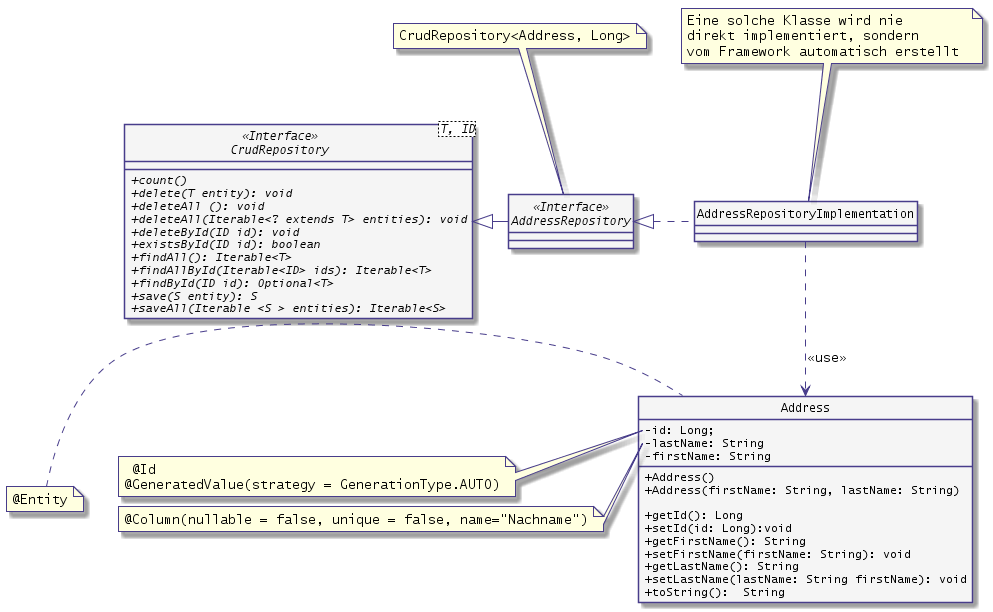
Es mag erstaunen, dass diese Repository-Interfaces nie direkt implementiert werden müssen: Spring sucht zunächst Implementierungen, versucht dann über Spring Data Abfragen automatisch zu generieren oder zuletzt die Methoden der Referenzimplementierung SimpleJpaRepository zu nutzen.

Vertiefung der Annotationen für das Modell
Erweiterung der Annotationen für Attribute
Es gibt eine ganze Reihe weiterer Annotationen, die verwendet werden können. Zum Teil sind diese an eine spezielle Implementierung der JPA (i.d.R. Hibernate) gebunden und nicht generell gültig.
@GeneratedValue(strategy = GenerationType.AUTO): hier können auch noch die StrategienIDENTITY,SEQUENCE, undTABLEausgewählt werden.@NotNull: kann auf Methoden, Attribute oder Parameter angewendet werden (bei Attributen kann auch@Column(nullable=false)gesetzt werden)@NaturalId: Sofern das Domänenmodell über einen natürlichen Schlüssel verfügt kann dieser hiermit annotiert werden.@NotEmpty: für Zeichenketten - verhindert Leerstrings.@Size(min = 10, max = 32): gibt an, wie lange eine Zeichenkette minimal / maximal sein darf
Nächste Schritte
Dieser Artikel ist ein Teil der Artikelserie zu einem Adressbuch-SpringBoot-Projekt.
Als nächstes sollte das Modell und das Repository einmal benutzt werden, um die Funktionalität zu verstehen und zu prüfen, ob alles so klappt, wie es soll. Dazu muss
Eine SpringBoot-Testumgebung geschaffen
für die wesentlichen Methoden (CRUD) jeweils ein Test geschrieben werden
Weiter geht es also mit dem Test des Modells über das Repository: Testen des Repositories.
Hinweis zur Nachnutzung als Open Educational Resource (OER)
Dieser Artikel und seine Texte, Bilder, Grafiken, Code und sonstiger Inhalt sind - sofern nicht anders angegeben - lizenziert unter CC BY-SA 4.0. Nennung gemäß TULLU-Regel bitte wie folgt: “Persistenzschicht und Modell” von Hannes Stein, Lizenz: CC BY-SA 4.0. Der Artikel wurde unter https://oer-informatik.de/sbb03_addressmodel veröffentlicht, die Quelltexte sind in weiterverarbeitbarer Form verfügbar im Repository unter https://gitlab.com/oer-informatik/java-springboot/Backend. Stand: 04.09.2023.
[Kommentare zum Artikel lesen, schreiben] / [Artikel teilen] / [gitlab-Issue zum Artikel schreiben]